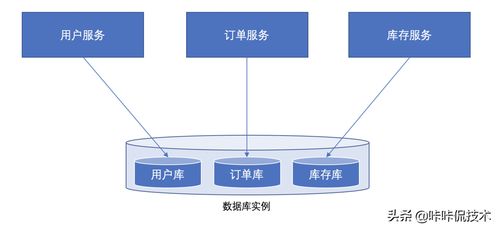
在微服务架构的实践中,有一条被广泛认可的核心原则:每个微服务应拥有其私有的、专属的数据库。这一原则常被形象地称为“数据库隔离”或“数据库封装”,而“共享数据库”则被视为一种反模式。面试中常问及的“为什么微服务不能共享数据库”,其答案深刻触及了微服务设计的本质与优势。
一、 核心矛盾:共享数据库违背了微服务架构的根本目标
微服务架构的初衷是将一个庞大的单体应用拆分为一组松耦合、独立部署、独立演进的小型服务。共享数据库恰恰与这些目标背道而驰:
- 破坏服务自治与松耦合:一旦多个服务直接读写同一数据库,它们之间就通过一个隐形的、强力的数据契约紧密绑定。一个服务对数据库表结构的修改(如增加字段、修改约束)会直接、不可控地影响其他所有依赖该表的服务,形成“数据库耦合”。这迫使服务间必须进行同步协调,丧失了独立演进的能力。
- 阻碍独立部署与扩展:服务的扩展性受限于共享数据库的瓶颈。即使某个服务(如订单服务)的读写压力剧增,需要进行数据库层面的垂直或水平拆分,也会因为其他服务(如用户服务、库存服务)的存在而变得极其复杂,甚至无法实施。
- 模糊领域边界与责任:共享数据库使得数据模型成为一个“大泥球”,难以清晰地映射到具体的业务领域(领域驱动设计中的“限界上下文”)。哪个服务负责哪些数据的完整性和业务逻辑变得模糊,导致代码混乱和维护困难。
二、 共享数据库带来的具体挑战与风险
从实践角度看,共享数据库会引入一系列棘手的问题:
- 数据一致性的两难:在分布式系统中,维护跨服务的数据一致性本应通过Saga、事件驱动等模式在应用层显式处理。共享数据库诱使开发者滥用数据库事务(如分布式事务)来保证一致性,这在高并发、跨网络环境下性能极差,且将服务重新耦合回单体模式。
- 技术栈锁死:所有服务必须使用同一种数据库技术和客户端驱动,无法根据特定数据访问模式(如订单服务用关系型数据库,商品搜索服务用Elasticsearch)选择最合适的工具,丧失了技术多样性带来的优势。
- 安全与权限管理复杂化:需要在数据库层面为不同服务配置精细到表甚至行级的访问权限,管理复杂且容易出错。而私有数据库则允许每个服务使用统一的、高权限的账户,简化安全模型。
- 故障隔离性差:一个服务编写了低效的SQL查询或触发了数据库锁,可能耗尽连接池资源,导致整个数据库性能雪崩,进而拖垮所有依赖它的服务,故障范围被放大。
三、 正确实践:服务间如何“交流”数据?
禁止共享数据库,并不意味着服务间不能交换数据。正确的做法是通过定义良好的API接口(通常是RESTful API或gRPC) 进行同步通信,或通过发布/订阅领域事件进行异步通信。
- API集成:服务A需要服务B的数据时,通过调用B提供的API获取。这确保了B对其数据的完全掌控和封装,内部数据结构的变更只要不影响API契约,就不会波及A。
- 事件驱动:当服务内的数据状态发生变化(如“订单已创建”),它向消息中间件发布一个事件。其他感兴趣的服务订阅这些事件,并在本地维护一份自己需要的数据副本(读模型)。这种方式实现了服务的彻底解耦和最终一致性。
四、 结论与例外
微服务不共享数据库,是为了捍卫自治、松耦合、独立演进这些架构核心价值。它强制在服务边界上建立清晰、可控的契约,而非隐晦、易变的数据依赖。
在极少数场景下,如迁移遗留系统的初期、或处理全局性的、极少变更的参考数据(如国家地区编码表),可能会暂时或策略性地允许有限度的共享。但这应被视为过渡方案或特例,而非标准实践。
因此,当面试官提出“为什么微服务不能共享数据库”时,其期待的不仅是技术风险的罗列,更是对微服务哲学——通过清晰的边界和契约来管理复杂性——的深刻理解。回答此题,便是展示你从架构原则到工程实践的系统性认知。









